
阿里云开源通义千问多模态视觉模型Qwen-VL 可商用
8月25日,阿里云在魔搭社区开源了,通义千问多模态视觉模型Qwen-VL。Qwen-VL支持多图输入和比较,指定图片问答,多图文学创作,在图片里中英双语的长文本识别等功能。同时Qwen-VL是首个开源448分辨率的LVLM模型,更高的分辨率有助于提升细粒度的文字识别、文档问答和检测框标注。
开源地址:https://modelscope.cn/models/qwen/Qwen-VL-Chat/files
目前,Qwen-VL提供了Qwen-VL和Qwen-VL-Chat两个模型。
Qwen-VL:以Qwen-7B的预训练模型为语言模型的基础,OpenclipViT-bigG为视觉编码器的初始化,中间加入单层随机初始化的cross-attentiON,经过约1.5B的图文数据进行训练,使得图像输入分辨率扩大至448。
Qwen-VL-Chat:在Qwen-VL的基础上,使用对齐机制打造了基于大语言模型的视觉AI助手Qwen-VL-Chat。训练数据涵盖了QWen-7B的纯文本SFT数据、开源LVLM的SFT数据、数据合成和人工标注的图文对齐数据。
阿里云从两个角度评测了两个模型的能力:
1、在英文标准Benchmark上评测模型的基础任务能力。目前评测了四大类多模态任务:Zero-shotCaption、GeneralVQA、Text-basedVQA、Referring Expression Compression。
2、试金石(TouchStone):为了评测模型整体的图文对话能力和人类对齐水平。为此构建了一个基于GPT4打分来评测LVLM模型的Benchmark:TouchStone。
在TouchStone-v0.1中,评测基准总计涵盖300+张图片、800+道题目、27个类别。包括基础属性问答、人物地标问答、影视作品问答、视觉推理、反事实推理、诗歌创作、故事写作,商品比较、图片解题等尽可能广泛的类别。
为了弥补目前GPT4无法直接读取图片的缺陷,给所有的带评测图片提供了人工标注的充分详细描述,并且将图片的详细描述、问题和模型的输出结果一起交给GPT4打分。评测同时包含英文和中文版本。
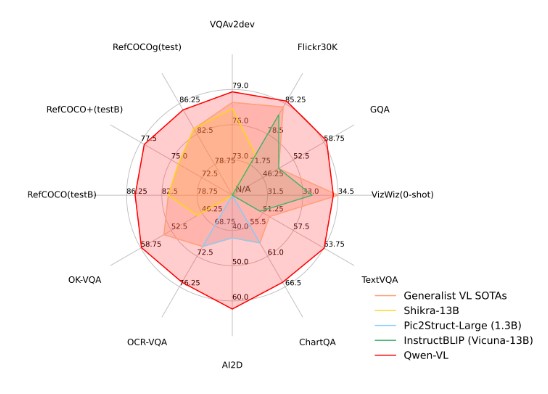
测试结果显示:在Zero-shotCaption中,Qwen-VL在Flickr30K数据集上取得了SOTA的结果,并在Nocaps数据集上取得了和InstructBlip可竞争的结果。
在GeneralVQA中,Qwen-VL取得了LVLM模型同等量级和设定下SOTA的结果。
在文字相关的识别/问答评测上,取得了当前规模下通用LVLM达到的最好结果。
Qwen-VL将分辨率提升到448,可以直接以端到端的方式进行以上评测。Qwen-VL在很多任务上甚至超过了1024分辨率的Pic2Struct-Large模型。
在定位任务上,Qwen-VL全面超过Shikra-13B,取得了目前GeneralistLVLM模型上在Refcoco上的SOTA。
Qwen-VL并没有在任何中文定位数据上训练过,但通过中文Caption数据和英文Grounding数据的训练,可以Zero-shot泛化出中文Grounding能力。Qwen-VL-Chat模型在中英文的对齐评测中均取得当前LVLM模型下的最好结果。

相关文章
发表评论
评论列表
- 这篇文章还没有收到评论,赶紧来抢沙发吧~