全球服务器测评
全球服务器测评Linux服务器跑久了之后,最常见的一个“隐性问题”就是内存看起来越来越紧张,有时候top一看,内存几乎被吃满,但业务又没明显增长;更糟糕的是,系统突然卡顿甚至SSH都连不上,日志里一翻才发现是 OOM Killer 出手把进程直接杀了。很多人第一反应是“是不是内存不够”,但实际情况往往没这么简单,大多数问题不是“内存小”,而是“内存没被正确理解和管理”。
这篇文章不讲理论空话,按真实排查路径走一遍:从现象识别、OOM分析、内存泄漏定位,到Swap策略优化,把一套完整的线上思路串起来。
一、先别慌:看起来“内存占满”不一定是问题
很多人登录服务器第一件事就是执行 free -h,然后看到类似:
Mem: 32G total, 30G used, 1G free, 500M buff/cache第一反应通常是:内存快爆了。
但在 Linux 里,这种判断方式是错误的。Linux 会尽可能利用空闲内存做缓存(page cache、buffer cache),以提升磁盘访问速度,所以“used 很高”并不等于“真的没内存”。
更正确的判断方式是看:
available而不是 free。
available 才是真正可以被应用使用的内存估算值,它考虑了缓存可回收空间。如果 available 还有几 GB,其实系统并不紧张。
另一个常见误区是 top 里的 RES 和 VIRT。很多人看到 VIRT 几十G就慌了,但 VIRT 只是虚拟地址空间,并不代表实际占用。真正要盯的是 RES(常驻内存)以及多个进程的累计趋势。
如果你只是看到“内存高”,但系统不卡,那大概率只是缓存策略正常运行,不需要动它。
二、OOM Killer 出现时,系统到底发生了什么
真正危险的情况是 OOM Killer 出现。它不是“报错”,而是 Linux 内核在极端内存不足时的最后手段:直接杀进程腾空间。
查看 OOM 记录一般用:
dmesg -T | grep -i oom你会看到类似:
Out of memory: Kill process 12345 (java) score 987 or sacrifice child
Killed process 12345 (java) total-vm:...这里有几个关键点需要理解:
第一,OOM 不是随机杀进程,它会根据 “score(评分)” 选择目标。评分越高,越容易被杀。影响因素包括:
- 占用内存大小
- 运行时间
- 是否 root 进程
- oom_score_adj 设置
第二,很多 Java、数据库、搜索引擎(比如 Elasticsearch)是高风险对象,因为它们通常吃内存多。
第三,OOM 发生前通常已经出现 swap 打满、系统卡顿、load 飙升等前兆,但很多人忽略了。
如果你想预防 OOM,可以做两件关键事情:
一是限制关键进程内存:
echo 500 > /proc/$(pid)/oom_score_adj或者 systemd 里设置:
MemoryMax=2G二是监控 available memory + swap usage,而不是只看 used。
三、内存泄漏的真实排查路径(比你想的更“脏”)
如果服务器长期运行内存持续上涨,最后逼近 OOM,那大概率是内存泄漏或“伪泄漏”。
常见三种情况:
1)应用层泄漏(最典型)
比如 Java、Node.js、Python 服务:
- 对象没有释放
- 缓存无限增长
- Map/Hash 不清理
- 连接池泄漏
这种情况特点是:进程 RSS 持续增长,并且不会回落。
排查方法:
top -p PID
pmap -x PID | sort -k3 -n或者:
smem -r如果你看到某个进程内存曲线是“单边上涨”,基本可以锁定应用问题。
2)缓存假增长(Linux cache)
很多时候不是泄漏,而是 Linux 在帮你“缓存”。
表现是:
- used 很高
- available 仍然正常
- 重启后内存“突然变干净”
可以用:
echo 3 > /proc/sys/vm/drop_caches测试前后差异,但注意生产环境不要随便清缓存。
3)句柄泄漏 / 文件泄漏
有些服务不是吃 RAM,而是吃“资源”,比如:
- 文件句柄泄漏
- socket 没关闭
- log 无限打开
查看:
lsof -p PID | wc -l如果持续增长,就是资源泄漏。
四、Swap:不是救命稻草,而是“缓冲区”
很多人对 swap 有误解,要么完全关闭,要么无限依赖。
实际上 swap 的定位是:缓冲压力,而不是替代内存。
swap 太小的问题
- OOM 更容易发生
- 突发流量无法缓冲
- 数据库容易崩
swap 太大的问题
- 系统开始疯狂换页
- IO 飙高
- 反而更卡(“假死状态”)
查看 swap:
free -h
swapon --show推荐策略(经验值)
一般线上服务器:
- 4G 内存以下:swap = 1~2倍 RAM
- 8~32G 内存:swap = 4~8G
- 数据库服务器:适当保留,但避免过度依赖
更关键的是 swappiness:
cat /proc/sys/vm/swappiness默认可能是 60,这对服务器来说偏高。
建议:
vm.swappiness = 10含义是:尽量用内存,少用 swap。
但注意:不是 0(避免极端 OOM)。
五、真实线上排查流程(一步一步做)
当你遇到“内存高 + 卡顿”时,可以按这个顺序:
第一步:确认是不是假内存问题
free -h重点看 available,而不是 used。
第二步:找内存增长进程
top或:
ps aux --sort=-%mem | head找出 Top 5 内存进程。
第三步:确认是否持续增长
隔 5~10 分钟执行一次:
watch -n 5 "ps -eo pid,cmd,%mem,rss --sort=-rss | head"如果某个 PID 一直涨 → 基本泄漏。
第四步:检查 OOM 记录
dmesg -T | grep -i oom如果有记录,说明已经发生过内核级别“自救”。
第五步:检查 swap 使用情况
free -h如果 swap 在增长 + IO 很高,说明已经进入“内存换页地狱”。
六、几个典型线上案例(非常真实)
案例1:Java服务慢慢变卡
现象:
- 内存逐渐上升
- CPU正常
- 最后 OOM
原因:
- JVM 堆设置过大
- 本地缓存无限增长
解决:
- 限制 -Xmx
- 加缓存过期机制
案例2:MySQL突然卡死
现象:
- load 飙升
- swap 100%
- SSH延迟
原因:
- buffer pool过大
- 查询突发
解决:
- 调整 innodb_buffer_pool_size
- 增加 swap + 降 swappiness
案例3:Docker容器集体崩溃
现象:
- 多个容器被杀
- dmesg 出现 OOM
原因:
- 没有限制 memory
解决:
--memory=2g
--memory-swap=2g七、系统级优化建议(长期稳定关键)
如果你想让 Linux 内存长期稳定,不只是“救火”,而是要做系统优化:
1. 控制缓存策略
vm.vfs_cache_pressure = 1002. 降低 swap 依赖
vm.swappiness = 103. 限制服务内存
systemd:
MemoryMax=Docker:
--memory4. 监控必须做
至少监控:
- available memory
- swap usage
- RSS top process
- OOM log
否则你只是在“猜问题”。
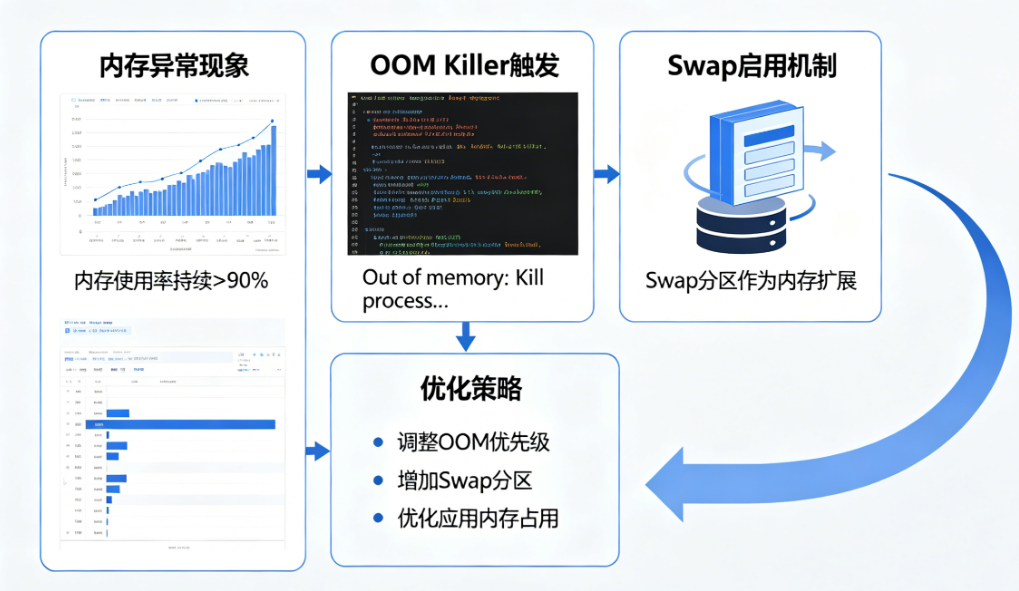
结尾:内存问题本质不是“容量问题”,而是“管理问题”
很多人一看到 Linux 内存高就想加内存,但真实情况是,大多数服务器的 OOM、卡顿、swap 风暴,都不是因为“内存不够”,而是因为:
- 缓存误判
- 应用泄漏
- swap 策略错误
- 没有限制进程资源
- 缺少监控
Linux 的内存机制本身是很激进的,它不是保守分配,而是“尽可能利用”。理解这一点之后,你会发现很多所谓“内存问题”,其实只是系统行为被误读了。