全球服务器测评
全球服务器测评一、问题出现时的第一反应:先别急着删文件
服务器磁盘空间告急这件事,很多人第一次遇到的时候都会比较慌,尤其是线上业务正在跑,日志突然写不进去、数据库报错、网站开始500,这时候最容易做的错误操作就是“看到大文件就删”,或者直接清空日志目录。实际上这种做法风险很高,因为你并不清楚哪些文件正在被进程占用,也不知道删掉之后是否会影响正在运行的服务,甚至有时候删掉文件,空间也不会立刻释放,因为文件句柄还被占着。
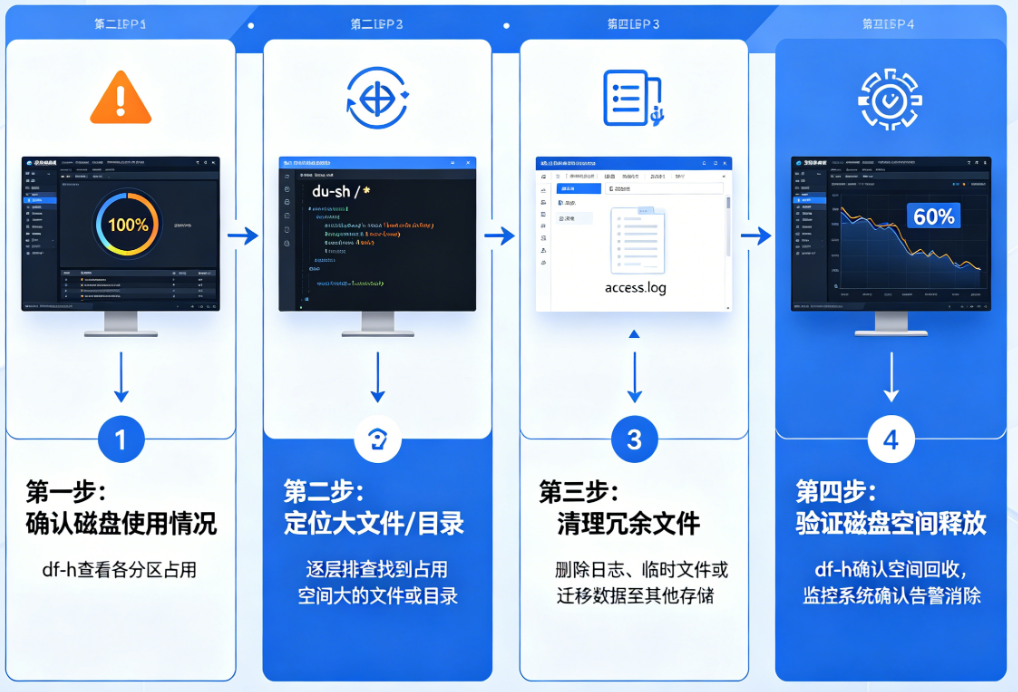
更合理的第一步,是先确认问题的真实性和范围。可以通过 df -h 先看整体磁盘使用情况,重点关注是否某个分区达到 90% 甚至 100%。如果只是某个挂载点满了,而系统盘还正常,那问题范围就已经缩小很多了。接着再用 df -i 看 inode 是否耗尽,有时候磁盘空间还有,但 inode 用完一样会导致无法写入,这种情况在大量小文件(比如缓存、session、日志碎片)场景里非常常见。
确认问题之后,不要急着动文件,而是先判断“是谁占了空间”,这一步才是真正排查的核心。
二、定位磁盘占用:从“看起来大”到“真正大”
真正开始排查的时候,du 和 ncdu 是最关键的工具。很多人会直接用 du -sh /*,但这只是粗粒度扫描,真正建议的方式是从根目录逐级往下拆:
du -h --max-depth=1 /先看 /var、/home、/usr 哪个目录异常大,一般来说问题集中在 /var。比如 /var/log 日志爆炸、/var/lib/docker 容器镜像堆积、/var/cache 缓存没有清理,这些都是高频“罪魁祸首”。
如果服务器装了 Docker,那么 /var/lib/docker/overlay2 很可能是磁盘占用大户,这种情况不能直接删除文件,而要通过 docker system df 和 docker system prune 逐步清理未使用的镜像、容器和 volume,否则容易误删正在运行的依赖层。
另外一个容易被忽视的点是“删除了但空间没释放”。用 lsof | grep deleted 可以查到被进程占用但已经删除的文件,比如日志文件被 rm 掉了,但 nginx、java 进程还在写,这种情况下必须重启相关进程才能真正释放空间,否则 df 永远不变。
三、日志系统:最常见的空间杀手
在绝大多数 Linux 生产服务器上,磁盘爆满的第一元凶几乎都是日志系统失控。无论是 nginx、tomcat、spring boot 还是系统 syslog,一旦没有做日志轮转,几天时间就可能写满磁盘。
先看 /var/log:
du -sh /var/log/*如果看到单个日志文件达到几个 G、甚至几十 G,那基本可以确定是日志策略问题,而不是偶发异常。此时不要直接删除日志,而是优先做三件事:
第一是开启 logrotate 或检查 logrotate 是否正常工作。很多服务器虽然有 logrotate,但配置错误或者 cron 没执行,导致日志一直追加不切割。
第二是对当前大日志进行“安全清理”,可以用 echo > filename.log 清空文件内容,而不是 rm 文件,这样不会影响进程句柄。
第三是回溯业务异常,如果某个日志突然暴涨,比如 error.log 一小时增长 5G,说明系统本身已经有异常循环或错误刷屏,这时候清理只是治标,必须定位根因,否则磁盘问题还会再次出现。
四、缓存与临时文件:隐藏的空间消耗
除了日志之外,缓存也是第二大隐形空间消耗源。比如 yum 缓存:
yum clean all或者 apt 系统:
apt-get clean这些操作可以直接释放大量安装包缓存。
另外 /tmp 和 /var/tmp 也经常被忽略,有些程序会在这里写临时文件但不会自动清理,尤其是导入导出任务、备份任务失败后残留文件,时间一长就会占满磁盘。
systemd 的 journal 日志也经常成为隐藏大头,可以通过:
journalctl --disk-usage
journalctl --vacuum-time=7d来限制日志保留时间,否则 journal 很容易占用数GB甚至十几GB空间。
五、扩容之前必须做的判断:是真不够还是假满
在动“扩容”这个操作之前,需要先判断一个问题:当前磁盘是不是真的设计不够,还是临时爆量。
如果是短期日志暴涨、异常流量、或者容器失控,那么扩容只是延缓问题,并不会解决本质问题。反而会让你“更不敏感”,等下一次爆满时更难发现。
但如果业务已经稳定增长,比如数据库持续变大、用户上传文件持续增加,那么扩容就是必然步骤。
这时候要看当前磁盘类型:是云盘还是物理机本地盘。
云服务器(如 AWS、阿里云、腾讯云)一般支持在线扩容磁盘,但扩容后还需要在系统内部进行分区扩展,比如:
growpart /dev/vda 1
resize2fs /dev/vda1或者 xfs 文件系统:
xfs_growfs /如果是物理机或 VPS,可能需要挂载新磁盘,比如:
fdisk -l
mkfs.ext4 /dev/sdb
mount /dev/sdb /data然后再通过 fstab 做自动挂载。
六、结构优化:真正长期解决磁盘问题的方法
很多人解决磁盘满的问题是“删+扩”,但真正稳定的服务器维护,必须有结构优化思维。
第一是日志分层,把日志分为 access、error、debug,并设置不同保留周期,比如 error 保留 30 天,access 保留 7 天,debug 只保留 1 天甚至关闭。
第二是业务数据与系统盘分离,不要把数据库、上传文件、缓存全部放在 / 盘,否则迟早会爆。标准做法是单独挂载 /data 或 /var/lib/mysql。
第三是定期自动清理机制,比如 cron 定时任务:
0 3 * * * find /var/log -type f -mtime +7 -delete或者使用更安全的 logrotate 策略,而不是人工清理。
第四是监控系统必须上线,比如通过 node_exporter + grafana 监控磁盘增长趋势,而不是等 100% 了才处理。
七、一次完整事故处理流程总结
真正成熟的磁盘告警处理流程,应该是这样的顺序:
先确认 df 是否异常 → 再查 inode → 再定位 du 大目录 → 再排查日志和缓存 → 再检查是否 deleted 文件未释放 → 最后才考虑扩容。
而不是一上来就扩容,也不是看到大文件就删除。
很多服务器问题看起来是“磁盘不够”,但本质其实是“没有治理机制”。磁盘只是结果,不是原因。
如果能把日志管理、缓存清理、数据分盘、监控预警这几件事做好,磁盘爆满这种问题基本会从“突发事故”变成“可预测事件”,处理成本会下降很多。