 全球服务器测评
全球服务器测评在日常 Linux 运维中,Debian系统的服务管理是绕不开的一环。无论是部署网站、运行数据库,还是维护后台任务,最终都会落到“服务如何启动、如何稳定运行、如何排障”这些具体问题上。而 systemd 作为 Debian 目前默认的初始化与服务管理体系,几乎已经覆盖了整个系统生命周期的控制逻辑。如果只是停留在“systemctl start/stop”这种表层操作,其实很难真正应对生产环境里的复杂问题。要把 Debian 服务管理用顺手,需要从系统结构、服务机制、日志体系以及故障思路几个层面建立一套完整认知。
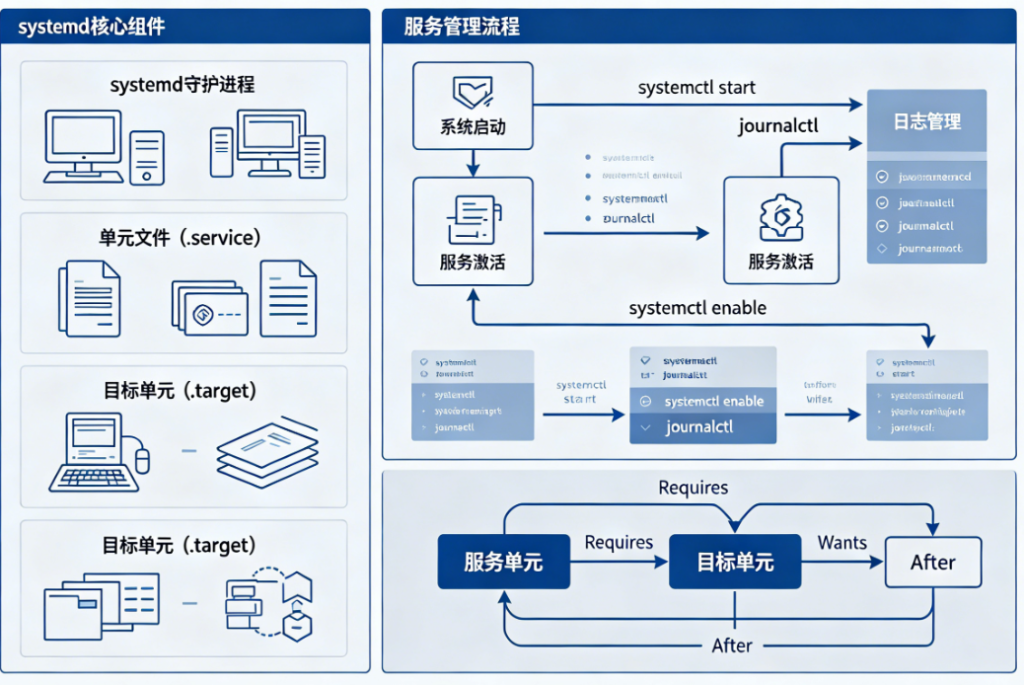
一、systemd 在 Debian 中的角色与运行逻辑
在传统 Linux 体系中,服务管理曾经是分散且碎片化的,比如 SysVinit 依赖脚本顺序启动,Upstart 又引入了事件机制,但整体仍然难以统一管理。而 systemd 在 Debian 中的核心作用,就是将“系统启动”和“服务管理”整合成一个统一的控制平面。它不仅负责启动第一个进程(PID 1),还负责后续所有守护进程的调度与依赖关系处理。
理解 systemd 的关键在于一个概念:依赖驱动的并行启动机制。系统启动时,systemd 会根据 unit 文件描述的依赖关系构建一张启动图,而不是简单的顺序执行脚本。这意味着 nginx、mysql、ssh 等服务可以在满足依赖条件的情况下并行启动,从而显著缩短启动时间。同时 systemd 还引入了 socket activation、D-Bus activation 等机制,使得服务甚至可以在“被访问时才启动”,减少资源浪费。
在 Debian 中,systemd 的 unit 文件通常分布在 /lib/systemd/system/(系统安装提供)以及 /etc/systemd/system/(用户自定义或覆盖配置)。这种分层结构非常关键,因为很多运维问题其实就出在“覆盖关系不清晰”,比如你修改了 service 文件但没有 reload daemon,或者错误地在系统目录与本地目录之间产生冲突。
二、服务生命周期管理的基本操作逻辑
从运维角度来看,systemd 的服务管理可以归纳为几个核心动作:启动、停止、重启、重载以及状态查看。这些操作看似简单,但在生产环境中往往需要结合上下文判断。
例如 systemctl start nginx 并不仅仅是“启动服务”,而是触发 systemd 读取 nginx.service unit 文件,解析依赖,检查 socket 状态,随后调用 ExecStart 指令执行程序。如果服务启动失败,systemd 会记录退出码,并根据 Restart 策略决定是否自动拉起。
而 systemctl status 是一个经常被低估的命令,它不仅显示服务是否运行,还会展示最近的日志片段、主进程 PID、退出状态码等信息。在排查问题时,这些信息往往比单纯看日志更直接。
值得注意的是 reload 与 restart 的区别。在很多服务中,reload 只是“平滑加载配置”,不会杀掉主进程,例如 nginx reload 可以在不中断连接的情况下重新读取配置文件。而 restart 则是彻底重启服务,适用于进程异常或状态不可控的情况。很多线上事故其实就来自误用 restart 导致连接中断,因此必须根据业务特性谨慎选择。
三、Unit 文件结构与服务定义的本质
systemd 的核心并不是命令,而是 unit 文件。每一个服务、本地挂载点、设备甚至定时任务,都被抽象为一个 unit。理解 unit 文件结构,是掌握 Debian 服务管理的关键一步。
一个典型的 service unit 文件通常分为三个部分:[Unit]、[Service]、[Install]。
在 [Unit] 中定义的是服务的描述信息以及依赖关系,例如 After=network.target 表示该服务必须在网络初始化之后启动。这里的依赖关系不是简单的“先后顺序”,而是系统依赖图的一部分。
[Service] 部分则是核心执行逻辑,例如 ExecStart、ExecStop、Restart 等。这里需要特别注意 Type 参数,它决定 systemd 如何判断服务“已经启动成功”。例如 simple 表示直接认为进程启动即成功,而 forking 则适用于后台守护进程模型。
[Install] 部分则与 enable/disable 有关,决定服务是否在开机时自动启动。很多人只会用 enable,但其实 systemd 是通过创建符号链接实现的,这意味着你可以手动控制启动目标(multi-user.target 等)。
理解 unit 文件的意义在于,你不再只是“操作服务”,而是在“定义服务行为”。这一步是从使用者走向运维工程思维的分水岭。
四、日志系统 journalctl 的核心价值
在 Debian systemd 体系中,日志不再依赖传统的 /var/log/ 分散文件,而是统一由 journald 管理。这带来一个非常重要的变化:日志成为结构化数据,而不是简单文本。
通过 journalctl -u nginx 可以直接查看某个服务的完整日志链路,而无需手动翻文件。这对于排查间歇性故障尤其重要,比如服务凌晨崩溃、或者负载异常波动。
更重要的是,journalctl 支持时间过滤与优先级过滤,例如:
journalctl -u mysql --since "1 hour ago"journalctl -p err
这种能力让运维排查从“翻日志”变成“定位事件”。
但需要注意的是,journald 默认日志是存储在内存或受限磁盘空间中的,如果没有配置持久化(/var/log/journal),重启后日志可能丢失。在生产环境中,这一点经常被忽略,从而导致“事后无法追溯问题”。
此外 systemd 日志还支持结构化字段,例如 _PID、_COMM 等,这使得日志分析可以进一步自动化,甚至可以接入 ELK 或 Loki 体系进行集中处理。
五、常见故障排查思路与实践方法
在实际运维中,systemd 服务问题通常不会直接表现为“启动失败”,而是更隐蔽的状态,例如服务启动成功但无法访问、服务频繁重启、或者资源异常占用。
第一步永远是 systemctl status,确认服务当前状态以及退出码。如果出现 failed 状态,需要重点关注 ExitCode 与日志摘要。很多时候问题已经被 systemd 直接记录。
第二步是 journalctl 定位具体错误,例如端口冲突、权限不足、配置文件错误等。这些信息往往比应用日志更早出现。
第三步需要检查依赖关系,例如网络未就绪导致服务启动失败,这类问题通常表现为 After=network.target 不足以保证网络可用,需要改为 network-online.target。
第四步是资源问题,包括 CPU、内存、文件句柄限制等,可以通过 systemctl show 或 cgroup 信息查看。systemd 的一个优势就是所有服务都运行在 cgroup 中,因此资源隔离是可追踪的。
在处理复杂问题时,一个常见误区是“只看应用日志”,而忽略 systemd 本身的调度行为。实际上很多问题根源在 systemd 配置,而不是应用本身。
六、进阶实践:服务优化与系统级控制
当你不再满足于“能启动服务”,就会进入优化层面。systemd 提供了大量控制参数,例如 CPUQuota、MemoryLimit、TasksMax 等,可以直接限制服务资源使用,这在多服务共存的 VPS 或生产服务器上非常重要。
此外,通过 Restart=always 或 on-failure 可以增强服务自愈能力,使系统在异常情况下自动恢复。但也要避免“无限重启循环”,否则会掩盖真实问题。
定时任务方面,systemd timer 已经可以部分替代 cron,它支持更精确的时间控制与日志统一管理,例如按分钟级别调度、延迟启动、依赖触发等。
更进一步,还可以通过 systemd target 构建不同运行模式,例如 rescue mode、multi-user mode,这在维护和灾备场景中非常实用。
Debian 的 systemd 并不仅仅是一个“服务管理工具”,而是整个系统运行逻辑的中枢。从启动流程到资源管理,从日志系统到故障恢复,它实际上定义了现代 Linux 的运维方式。很多初级使用者停留在 systemctl 的表面操作,而真正的差距在于是否理解 unit 结构、依赖图以及日志体系之间的关系。
